応用編:さまざまなクエリパターン#
InfluxDBを使いこなすには、Grafana等に埋め込むflux言語の記述方法について学んでおく必要があります。
ダウンサンプリング#
TF6420で収集したTwinCATの高速サイクル処理データは、すべてInfluxDBに記録されています。このデータ全てを取り出と膨大なデータとなり非常に扱いにくいです。このため適用アプリケーションに求められる解像度へ落とし、扱いやすくすることが求められます。任意のサンプリング解像度に下げることを、「ダウンサンプリング」と呼びます。
このためのflux言語は下記1行です。
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
aggregateWindow関数は、一定期間(Window)毎に任意の関数で集計した値にデータを集約します。Window単位にデータを粗くすることができます。関数の引数は以下のものがありますので、適切に設定してお使いください。
every設定値は、influxDBやGrafanaのそれぞれのダッシュボードのマクロ変数
v.WindowPeriodにより指定されます。この個所
v.WindowPeriodを、直接任意の値を設定することでwindow期間を設定することができます。1ms1ミリ秒、1s1秒、1m1分、1h1時間、1d1日、1w1週間、1mo1か月、1y1年fn集計に適用する関数を指定します。
meanwindow期間の集合の平均処理を行います。
medianwindow期間の集合の中央値を採用します。
lastwindow期間の最終値を採用します。
createEmpty収集できている時間間隔よりも短い集計期間が設定されるとデータが空になります。このとき、空のテーブル値を出力します。デフォルトはtureですので、無効化させるには明示的にfalseを設定します。
他にも引数があります。詳しくはこちらのドキュメントをご覧ください。
行列変換#
influxDBで抽出したテーブルは、_time列に時刻が、_field列にフィールドが、_valueにその値が格納された縦持ちリストとなっています。(table_default_influxdb_query)
_time |
module_name |
_field |
_value |
|---|---|---|---|
2023-12-08 10:00:00.000 |
XTS1 |
position |
122.99843 |
2023-12-08 10:00:00.000 |
XTS1 |
set_position |
123.0000 |
: |
これをpivot関数にて横持ちテーブルへ変換することができます。引数で、行を_time, 列を_fieldその値を_valueとなるように行列変換を行うコマンドは以下のとおりです。
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
この結果、次の通りとなります。
_time |
position |
set_position |
|---|---|---|
2023-12-08 10:00:00.000 |
122.99843 |
123.0000 |
: |
二つのフィールドの値同士を計算した新たなフィールドを定義する#
設定位置(set_position)と、現在位置(position)をプロットするクエリは下記の通りです。
from(bucket: "machine_monitoring")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "MotionActivityData")
|> filter(fn: (r) => r["_field"] == "position" or r["_field"] == "set_position")
|> filter(fn: (r) => r["module_name"] == "XTS1")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")
このクエリをGrafanaで可視化すると次図の通りとなります。このスケールではset_positionもpositionも重なって表示されてしまっています。このpositionとset_positionだけのデータからクエリで編差を計算し、可視化してみましょう。
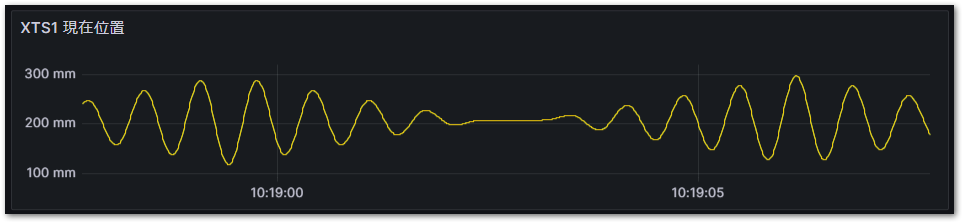
まず最初に、行列変換を行います。前項のとおりpivot()を使って行列変換を行います。
_time |
module_name |
_field |
_value |
|---|---|---|---|
2023-12-08 10:00:00.000 |
XTS1 |
position |
122.99843 |
2023-12-08 10:00:00.000 |
XTS1 |
set_position |
123.0000 |
: |
_time |
position |
set_position |
|---|---|---|
2023-12-08 10:00:00.000 |
122.99843 |
123.0000 |
: |
次に新たにdiffという列を追加してset_positionからpositionの差を計算した値をセットします。データを加工して新たな値を生み出すにはmap()関数を用います。
|> map(fn: (r) => ({r with diff: r.set_position - r.position}))
この結果、次の通りとなります。
_time |
position |
set_position |
diff |
|---|---|---|---|
2023-12-08 10:00:00.000 |
122.99843 |
123.0000 |
0.00157 |
: |
欲しいのは偏差だけなので、positionとset_position列は削除します。
|> drop(columns: ["set_position", "position"])
最後にGrafana等の表示スケールに合わせて自動的にダウンサンプリングする命令を加えます。ダウンサンプリングに用いる関数はmean(平均化)です。他にも中央値median, 最小min、最大maxなどがあります。
ダウンサンプリングを加えておかないとPLCの高速サイクルデータのそのままの精度をグラフ表示しようとして、あっという間にリソース不足になってしまいます。(その前にGrafana側でエラーが発生しますが・・・)
|> aggregateWindow(column: "diff", every: v.windowPeriod, fn: mean, createEmpty: false)
これで時刻と位置偏差だけのデータになります。まとめると次のクエリとなります。
from(bucket: "machine_monitoring")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "MotionActivityData")
|> filter(fn: (r) => r["_field"] == "position" or r["_field"] == "set_position")
|> filter(fn: (r) => r["module_name"] == "XTS1")
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({r with diff: r.set_position - r.position}))
|> drop(columns: ["set_position", "position"])
|> aggregateWindow(column: "diff", every: v.windowPeriod, fn: mean, createEmpty: false)
_time |
diff |
|---|---|
2023-12-08 10:00:00.000 |
0.00157 |
: |
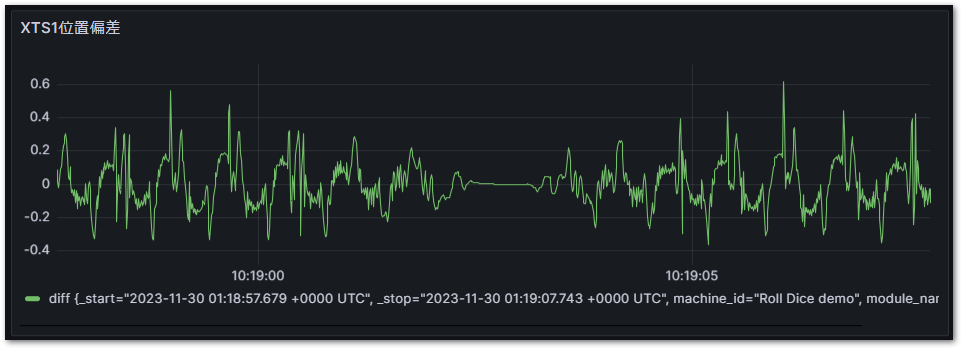
これをGrafanaで可視化したものが次のとおりです。単なるpositionとset_positionだけでは見えなかった精度での編差が可視化できました。
アラームやイベントの発生期間を調べる#
イベントのタイトルがtextフィールドに、その変化後の状態がboolean型でstatusフィールドに記録されるEventLoggerメジャメントをクエリする例です。次の手順でデータ加工を行います。
pivotにより、_fieldに記載されたフィールド名毎に列を分けた表に変換します。
イベント種類である
text毎にグループ化します。events.durationによりtrue/false間それぞれの間隔を秒数で計算し、duration列に出力します。
注釈
events.durationについては以下をご参照ください。unitを変更することでより精度の高い間隔時間を計算することができます。
https://docs.influxdata.com/flux/v0/stdlib/contrib/tomhollingworth/events/duration/
これにより、イベントの発生時刻、解消時刻と、その間隔が一覧される表が出力されます。
import "array"
import "contrib/tomhollingworth/events"
from(bucket: "machine_monitoring")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "EventLogger")
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
|> group(columns: ["text"])
|> events.duration(unit: 1s)
|> yield(name: "mean")
クエリにより得られたデータをCSVに出力した結果例は以下の通りです。
#group |
false |
false |
false |
false |
false |
false |
false |
false |
false |
false |
false |
false |
true |
false |
#datatype |
string |
long |
dateTime:RFC3339 |
dateTime:RFC3339 |
dateTime:RFC3339 |
string |
string |
string |
string |
string |
long |
boolean |
string |
long |
#default |
mean |
|||||||||||||
result |
table |
_start |
_stop |
_time |
_measurement |
machine_id |
module_name |
uuid |
event_id |
severity |
status |
text |
duration |
|
0 |
2023-11-29T21:00:00Z |
2023-11-30T09:01:00Z |
2023-11-29T23:35:34.911Z |
EventLogger |
Roll Dice demo |
Event |
11881C9C-6ABE-4B99-86DD-C74B4FE79496 |
1 |
3 |
true |
!! EMO Stop !! |
667 |
||
0 |
2023-11-29T21:00:00Z |
2023-11-30T09:01:00Z |
2023-11-29T23:46:42.498Z |
EventLogger |
Roll Dice demo |
Event |
11881C9C-6ABE-4B99-86DD-C74B4FE79496 |
1 |
3 |
false |
!! EMO Stop !! |
4351 |
||
0 |
2023-11-29T21:00:00Z |
2023-11-30T09:01:00Z |
2023-11-30T00:59:13.723Z |
EventLogger |
Roll Dice demo |
Event |
11881C9C-6ABE-4B99-86DD-C74B4FE79496 |
1 |
3 |
true |
!! EMO Stop !! |
17 |
||
0 |
2023-11-29T21:00:00Z |
2023-11-30T09:01:00Z |
2023-11-30T00:59:31.427Z |
EventLogger |
Roll Dice demo |
Event |
11881C9C-6ABE-4B99-86DD-C74B4FE79496 |
1 |
3 |
false |
!! EMO Stop !! |
384 |
||
0 |
2023-11-29T21:00:00Z |
2023-11-30T09:01:00Z |
2023-11-30T01:05:55.983Z |
EventLogger |
Roll Dice demo |
Event |
11881C9C-6ABE-4B99-86DD-C74B4FE79496 |
1 |
3 |
true |
!! EMO Stop !! |
6 |